

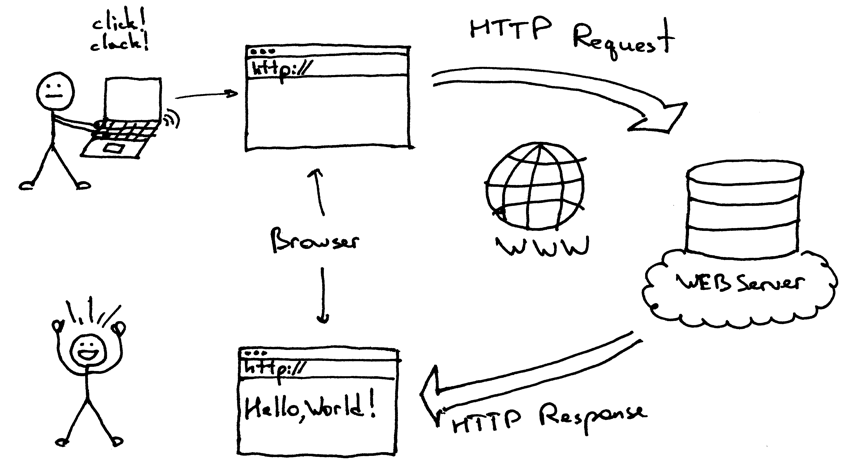
There’s too much data to handle in the modern-day internet facility. With this comes the concept of websites that hold a large amount of data about various things in the world.
While websites carry a large amount of data, it is hard to find the data that is relevant for a particular user. This is where the concept of web scraping and Scrapingpass.com come in.
- It is the act of extracting the needed and relevant data from any website that a user needs and we are excellent at it. We have everything that a developer would need to scrape website information.
- Our methodology and tools are based on quick and efficient extraction of information and support multiple languages for user convenience.
Below, we will discuss the best 7 JavaScript web scraping libraries for the act of web scraping and you can also check the 10 best free web scraping tools.
Also, you can know more about scraping here.
Monash Data Fluency
Top JavaScript Web Scraping Libraries :
1. Request :
For implementing quick use of HTTP and JavaScript web scraping, this is one of the most used and simple libraries that are present in JavaScript.
- It’s quite easy to implement and understand & has a straightforward way of using it. Therefore one can easily use it without any difficulties for complexities.
- It also has an advantage because it supports HTTP5 that are directed by default.

Scraping out content from a page using Requests is as easy as passing an URL, as shown in the example below,
const request = require('request');
request('http://scrapingpass.com', function(er, res, bod) {
console.error('error: ',er) // print error
console.log('body: ',bod); //print request body
});
These are the most used and commonly found instructions that exist in the implementation of the library.
URL or Uniform Resource Locator:
It is the destination URL of the HTTP request made by the user
Method:
One of the HTTP methods like GET, DELETE, POST, which will be used.
Headers:
This is an object that will be used, and constitute HTTP headers (key-value)
Form:
The key value from the available data is contained by this object.
What are the advantages of using Requests?
Here are the advantages of using it :
- Authentication of HTTP
- Support in the form of Proxy
- A protocol that supports TLS/SSL
- Callback and streaming interfaces are supported
- The best part is that most of the HTTP methods are supported like the GET, POST, etc.
- Form uploads are supported.
- One can implement the use of custom headers.
2. Cheerio :
One of the famous JavaScript web scraping libraries goes by the name of Cheerio.
- It is famous as it gives the developers and the users freedom by allowing the users to focus on the data that is downloaded rather than the parsing of the data.
- Another great fact about Cheerio is that it is very flexible and reliable along with being fast which is a great combination to have.
- It has the same subset of the jQuery core and hence, the user can interchange the jQuery and cheerio environment in the implementation of JavaScript web scraping this overall makes it fast.
Starting with Cheerio is quite simple and here’s how to do it :
var cheer = require('cheerio');
$ = cheeri.load('<h1 id="heading">Hi Folks</h1>');
With this, the user can use the $ as he or she used to in jQuery
$('#heading').text("Hello Geeks");
console.log($.html()); // return html example : <h1 id="heading">Hello Geeks</h1>
In the end, the user will have to do the package requesting in npm install request. Here’s how to get www.google.co.in HTML contents into your shell in an efficient and easy way.
var request = require('request');
var cheerio = require('cheerio');
request('http://www.google.com/', function(err, resp, body) {
if (err)
throw err;
$ = cheerio.load(body);
console.log($.html());
});
What are the advantages of using Cheerio?
Let’s talk about the advantages :
- Cheerio being the subset of jQuery, there are many similarities between the syntax.
- The removal of DOM consistencies causes the user to see the brilliant API.
- In the process of parsing, manipulation, and rendering of the input data, Cheerio is quite fast and also, reliable.
- The best thing is that Cheerio is able to parse any kind of HTML or XTL file which is just great for the users.
3. Osmosis :
Osmosis is considered one of the most efficient and top-notch Javascript web scraping libraries.
- With Osmosis, complex pages can be scraped without the knowledge and use of much coding which is just great for most of the users.
- Osmosis scrapes and parse XML and HTML and is implemented in node.js, being packed along with css3/XPath selector, and also, there is a lightweight HTTP wrapper.
- Also, another thing is that unlike Cheerio, Osmosis has no huge dependencies which and it’s quite good.
cron-dev
To begin with, we can see below how using Osmosis, one can scrape a Wikipedia page which consists of a list of the popular Hindu festivals that are celebrated across India.
osmosis
.get('https://en.wikipedia.org/wiki/List_of_Hindu_festivals')
.set({ mainHeading: 'h1',
title: 'title'
})
data(list => console.log(list));
Here is the result :
{ mainHeading: 'List of Hindu festivals',
title: 'List of Hindu festivals - Wikipedia' }
Let us talk about the case wherein the user wants to find all the festivals.
This data, as seen, will be available on the next table on the same page. Therefore, the user will implement another function called ‘find’.
This will be useful in the selection of the current context with the usage of the selector. Thereafter, we tell Osmosis to collect the data from the first row, and in the end, we will achieve the results as desired.
osmosis
.get(url)
.set({ title: 'title' })
.find('.wikitable:nth-child(2) tr:gt(0)')
.set({festival:'td[0]'})
.data(list => console.log(list));
Let’s take a look at the result :
{ festival: 'Bhogi'}
{ festival: 'Lohri',}
{ festival: 'Vasant Panchami'}
...
What are the advantages of using Osmosis?
Here are a few of the many advantages that Osmosis has :
- Selector hybrids like the CSS 3.0 along with XPath 1.0 are very well supported.
- Proxy failure is easily handled
- Redirects and also retries the limits.
4. Puppeteer :
One of the great and efficient javascript web scraping libraries that were designed by the famous and trusted Google Chrome in the year 2018 performed much better than the performances by other great solutions like the Phantom JS or Selenium when compared in the relation with speed and efficiency.
This is just amazing.
Also, another great part is that it is quite stable and also, can be easily handled in Google’s Chome or Chromium browser.
So, the great features of this one are :
- Various form submissions can be efficiently automated.
- Screenshots can be easily made when needed
- Automation Testing can be created
- Creation of PDF from web pages on the internet
Here’s how to install the Puppeteer into the user project and then, run it :
npm install puppeteer
With this, a download of the latest Chromium version will take place.
One can also use the Puppeteer core if he or she seeks to run this onto the local Chrome browser itself.
What are the advantages of using Puppeteer?
Let’s check some advantages of Puppeteer :
- Point-and-click interface.
- Timeline trace if the user wants to find out any faults.
- This will allow the user to take screenshots.
- Web pages on the internet can be created into PDF files

Medium
5. Playwright
The playwright is another one of the good and reliable open JavaScript web scraping libraries that were developed by the same team that designed Puppeteer but, has moved on ever since.
- It’s designed such that it can automate Firefox chromium and also, Web Kit with the implementation of a single API.
- The aim of this is to be an alternative to WebDriver which is a giant in the field of W3C web automation.
If you want to install it, here’s how to :
npm i playwright
API is quite similar as observed below :
(async () => {
for (const browserType of ['chromium', 'firefox', 'webkit']) {
const browser = await playwright[browserType].launch();
const context = await browser.newContext();
const page = await context.newPage();
await page.goto('http://whatsmyuseragent.org/');
await page.screenshot({ path: `example-${browserType}.png` });
await browser.close();
}
})();
What are the advantages of using Playwright?
Here are some of the many advantages :
- The inputs from native mouse and keyboards are possible
- It is easy to upload as well as download the user files.
- There are scenarios that span multiple pages and iframes.
- Emulation of permissions and mobile devices
Apify blog
6. Axios
Axios can be easily used in the implementation of the front end and also, in the node. js-related back end and stands out of the many javascript web scraping libraries.
- Asynchronous HTTP requests are very easily sent to their REST point at the end.
- Also, CRUD operation performance is very easily done and their implementation becomes very easy because Axios has a very simple package which therefore allows the users to call the web pages from various other locations.
- The Axios library can be used in simple Javascript applications or can be used in collaboration with more complex Vue.js.
Let us take a scenario,
const axios = require('axios');
// Make a request for a client with a given token
axios.get('/client?token=12345')
.then(function (resp) {
// print response
console.log(resp);
})
.catch(function (err) {
// print error
console.log(err);
})
.then(function () {
// next execution
});
Then installing Axios :
npm i axios
This is how bower can be used :
bower install axios
or even yarn :
yarn add axios
What are the advantages of using Axios?
This is quite advantageous to those who know it :
- Requests can be easily aborted
- CSRF protection is already built-in
- Upload progress is supported
- JSON Data Transformation is an automatic process
7. Unirest
Quite a famous library for Javascript web scraping. Ruby, .Net, Python, and also, Java are all supported in this library.
Here is how Unirest is installed :
$ npm i unirest
Simplify requests as given :
var unirest = require('unirest');
What are the advantages of Unirest?
So, these are the advantages :
- Most of the HTTPS method like DELETE, etc are supported
- Forms uploads are supported in case users need them
- Autentication of HTTP is also present
What Does The Verdict Say?
These were some of the best scraping tools present. But, the one we use is ScrapingPass which is excellent in each way possible along with great services.
Using requests can be both, easy and friendly, standing out on the list. There are multiple streams of this river and with such great services, it outperforms most of the javascript web scraping libraries on the list.
But, in general, all of these libraries have performed brilliantly and served countless users. In the end, it all depends upon the user’s contemplation and decision which should be made after checking out his goal, and the features required.
So, it’s the user who has to choose the best from all the javascript web scraping libraries.




Abhishek Kumar
More posts by Abhishek Kumar