

Scraping is a common practice in the recent programming and fast-paced technological era. Many of us have been using scraping for our usual daily programming tasks.
But have you encountered a case when you are using requests or wget for accessing any webpage and getting a completely different HTML content?
Yes, you are not the only one to face this issue. Some developers are wise enough to save their precious data from any such crawler or scraper.
But have you wondered how can it smartly differentiate between a normal browser request and an automated python request.
In this blog, we will look at how this basically happens and how can we write a smart yet easy solution for such a problem using just a few lines of code in your favorite programming language ‘Python’.
In this blog, we will be covering each aspect of User-Agent. This blog is divided into several parts:
- What is a User Agent?
- Breakdown of a User-Agent
- Why do we need a User Agent?
- Steps involved in rotating User-Agent
What is a User Agent?
A User Agent is nothing but a simple set of strings that any application or any browser sends in order to access the webpage.
So now the question arises what basically are these strings which help the server to differentiate between a browser and a python script.
The components of a typical user-agent are as follows –
- the operating system
- application type
- software version, or
- software vendor of the requesting software user agent.
Now the question arises, “Why does information like operating system and software versions are required?”
Well, the answer is quite simple to optimize the webpage as per your hardware and software.
Let’s see an example of User-agent. We will be seeing an open-source developer’s favorite browser Mozilla Firefox.
Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTM, like Gecko) Chrome/51.0.2704.103 Safari/537.36
Breakdown of a User-Agent
Here in the above example, there are all the details which we talked about prior in this article. Now let’s breakdown and see which part is associated with it.
<browser>/<version> - Mozilla/5.0 (<system information>) - (X11; Linux x86_64) <platform> - AppleWebKit/537.36 (<platform-details>) - (KHTM, like Gecko) <extensions> - Chrome/51.0.2704.103 Safari/537.36
Now let’s see how a normal webpage request using standard python libraries such as ‘requests’ & ‘wget’ differs from a browser request. We will be considering ‘requests‘ for this example.
import requests
from pprint import pprint
# using HTTPBin to get the header for our requests
r = requests.get('http://httpbin.org/headers')
pprint(r.json())

Example of a user-agent
Why do we need a User Agent?
Now as we can see in the response itself, the user agent is ‘python-requests/2.24.0’. Hence this is how a server can recognize the difference between a normal browser request and python requests(). Now let’s see how can we change this user agent and replace this with a browser User-Agent using Python.
Now if you have observed the response we received has a dictionary and the key to it is ‘headers’. Now we have to map our user-agent into the python requests.
For our example, we will be taking the user-agent in the above example using requests.
headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTM, like Gecko) Chrome/51.0.2704.103 Safari/537.36 '}
r = requests.get('http://httpbin.org/headers', headers=headers)
pprint(r.json())

dummy user-agent
Now by using the above code we will get the output similar to a browser request ‘User-Agent’ as we can also see in the below image but remember it is not exactly similar as some components are still missing.
Let’s have a look at an actual browser request.
{
"headers": {
"Accept": "text/html.application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng*/*;q=0.8,application/signed-exchage;v=b3'q=0.9",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": 'en-GB,en-US;q=0.9,en;q=0.9",
"Dnt": "1",
"Host": "httpbin.org",
"Upgrade-Insecure-Requests": "1",
"user-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTM, like Gecko) Chrome/51.0.2704.103 Safari/537.36",
"X-Amzn-Track-Id": "Root=1-5ee7bae0-82260c065baf5d7f0533e5"
}
}
Now as we found some more things to be added in our header to fool-proof our User-Agent and header such as Accept-Language, Dnt, Upgrade-Insecure-Requests.
So we should edit the header a little bit more for it.
headers = {
"Accept": "text/html.application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng*/*;q=0.8,application/signed-exchage;v=b3'q=0.9",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": 'en-GB,en-US;q=0.9,en;q=0.9",
"Dnt": "1",
"Host": "httpbin.org",
"Upgrade-Insecure-Requests": "1",
"user-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTM, like Gecko) Chrome/51.0.2704.103 Safari/537.36"
}
r = requests.get('http://httpbin.org/headers', headers=headers)
pprint(r.json())
Now as we can see in the below response the output is the same as that of a browser.
A sigh of relief right now you can easily start your scraping without any worries of getting your IP-Address blocked right!
Well, it’s not done completely you are done halfway.
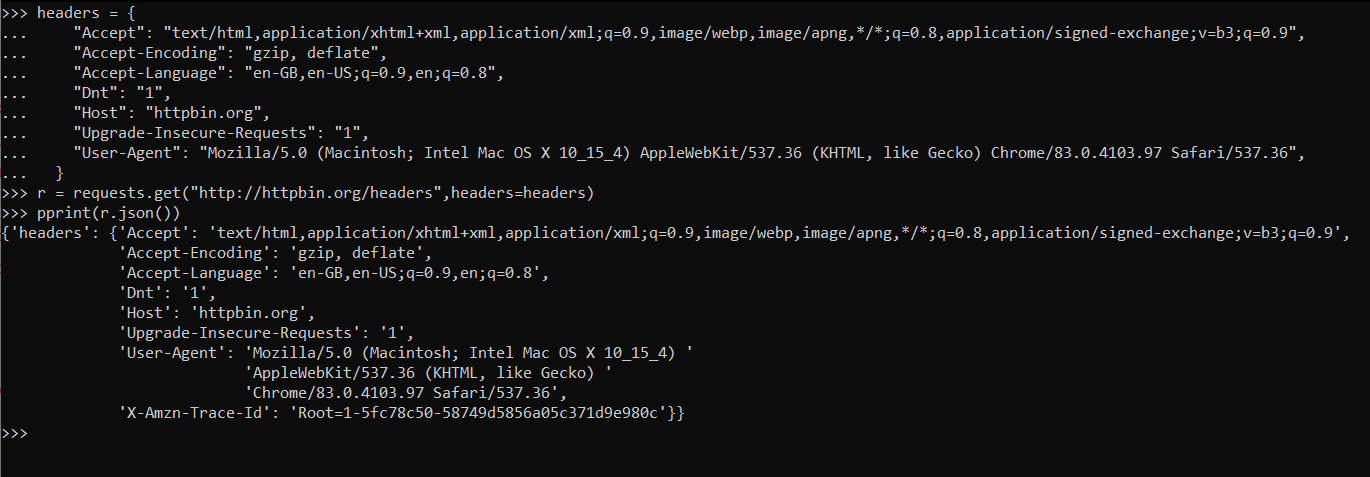
browser user agent sample
There are some things that needed to be taken care of before you can sit back and relax and that is User-Agent rotation.
It is nothing but a set of just above explained headers so that it can randomly pick one from and proceed without making requests with the same header and get blocked.
Steps involved in Rotating User Agents
Now If your goal is just rotating user agents, let’s discuss how we can implement this using the below steps. The process is very simple.
- You can collect a list of recent browser User-Agent by accessing the following webpage WhatIsMyBrowser.com.
- Save them in a Python list.
- Write a loop to pick a random User-Agent from the list for your purpose.
import requests
import random
user_agent_list = [
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_5) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.1.1 Safari/605.1.15',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:77.0) Gecko/20100101 Firefox/77.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:77.0) Gecko/20100101 Firefox/77.0',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36',
]
url = 'https://httpbin.org/headers'
for i in range(1,4):
# Pick a random user agent
user_agent = random.choice(user_agent_list)
# Set the headers
headers = {'User-Agent': user_agent}
# Make the request
response = requests.get(url,headers=headers)
print("Request #%d\nUser-Agent Sent:%s\n\nHeaders Recevied by HTTPBin:"%(i,user_agent))
print(response.json())
print("-------------------")
That’s all you needed to do in order to implement the User-Agent rotation using Python. Below is the output of the above code.
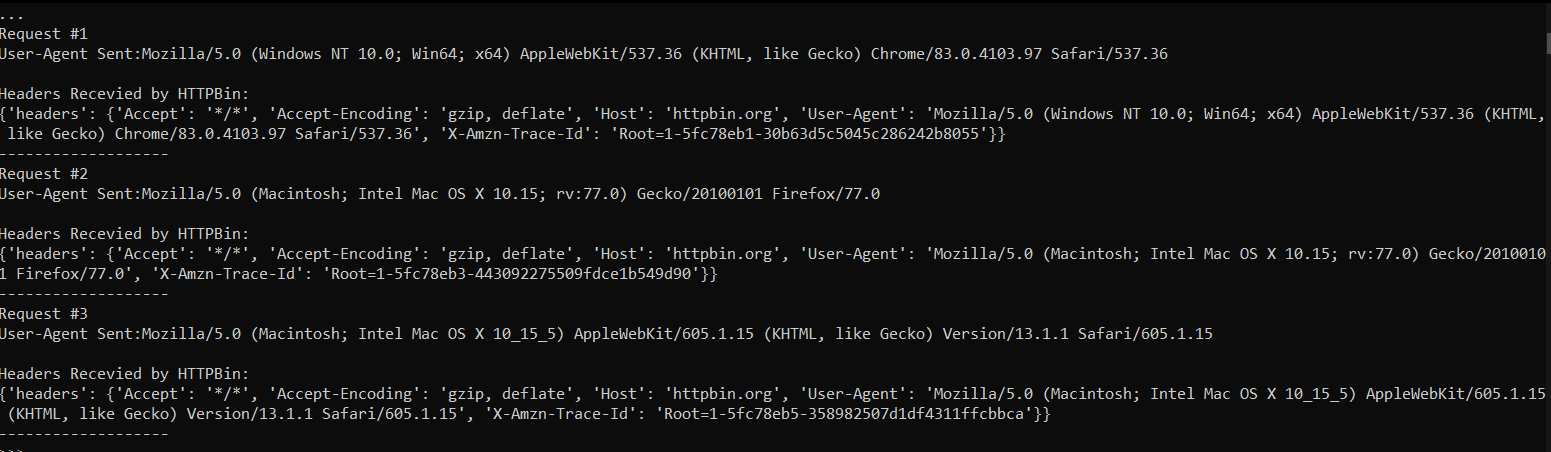
Final output for user-agent rotation
Congratulations you have successfully rotated the user-agent for a seamless scraping but some websites have some strict anti-scraping mechanism that can eventually detect this pattern also.
Though this process can be used it is a lot tedious than you can imagine. What we suggest is to use some tools for your hassle-free experience.
ScrapingPass is one of the best scraping service providers available today, providing an array of different services at extremely affordable pricing.




Abhishek Kumar
More posts by Abhishek Kumar