

Yahoo Finance has been around for quite some time and is the news holding of the web giant which goes by the name Yahoo!
In order to scrape this site, we offer our services to every person who seeks to implement the extraction of data. Information is a form of achievement and we offer this to you.
But, it is to be noted for all and any user that this article is meant only for the purpose of knowledge and education, and therefore, we at scrapingpass.com do not promote this kind of activity under illegal circumstances.
What Is Yahoo Finance?
- It has a collection of various kinds of reports, comments, releases, news, quotes, on the finance market and the current economy and also, includes all kinds of analysis of the market and quotes from top analysts who have been around for quite long and also, know their way around the market.
- Along with all this information, Yahoo Finance also contains some special tools for its users who seek financial support and management.
- The thing that makes Yahoo! Finance quite great and stand out is that every information is categorized, sorted, and is presented in a tabular form.
- This information can be easily implemented in the form of a web crawler that is used in the scraping process which can be very useful in telling if the information that is required or the target that is needed, is met or not.
- Although this might seem a very easy task with not much to be done, it actually requires great steps along with the proper implementation of web scraping.
Python Libraries To Scrape Data From Yahoo Finance :
Here are some of the most famous open-source libraries which will be used by us in the case of implementation of the said task of web scraping from Yahoo Finance and you can check more here :
- Beautiful Soup is a very famous and trusted product. Hence, it is the perfect tool for any user who wants to scrape information out of XML or HTML files and store them onto his device.
- Requests is also quite good and is responsible for proper requesting of the HTTP calls and also, proper management of the response in an efficient and clean way.
7 Steps For Scraping Finance Data From Yahoo :
1. The user has to make sure that the libraries are already installed and no delay is made.
This is because, in the case of any kind of delay, the user might have to handle errors that can be harmful to the whole scraping process, and hence, the following code should be implemented :
pip install requests pip install beautifulsoup4
2. It is necessary to have a great look at the webpage that the user is trying to scrape and gather information from in a general manner.
In order to get an understanding of the HTML structure of the entire webpage, it is necessary that the person who is involved in the activity inspects the element.
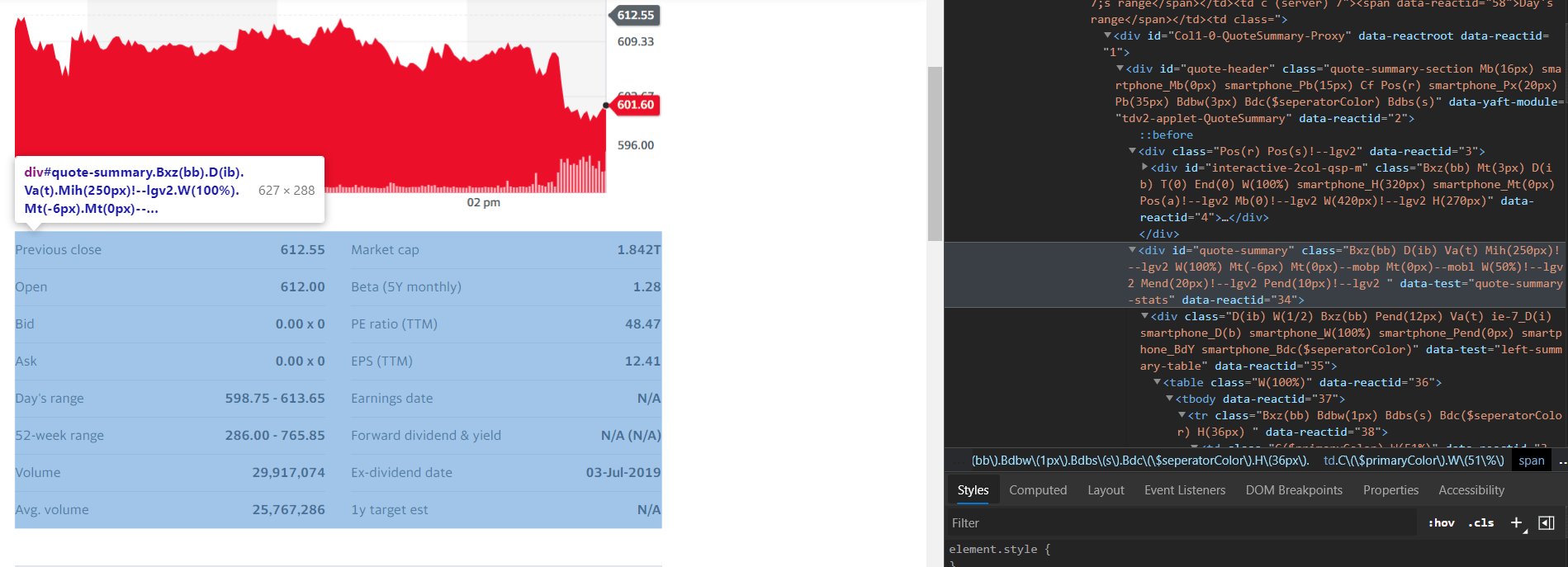
3. Requests library can be easily made to get the required data from the website that the user needs and the best part is that not much complex coding is needed rather, a much simple code of a few lines is required.
This is how the basic step for any kind of scaping process is taken. The user will have to import the required URL in order to fetch some container that is titled ‘URL’.
import requests from bs4 import BeautifulSoup url = 'https://in.finance.yahoo.com/quote/AXISBANK.NS?p=AXISBANK.NS&.tsrc=fin-srch' page = requests.get(url)
4. Now, the next step is the parsing of the extracted text into HTML structured data. This is where the beautifulsoup library comes into play as the user will implement it in the process of scraping.
This step too can be handled in a few lines of code as shown below :
soup = BeautifulSoup(page.text, 'html.parser')
data = soup.find_all('tbody')
5. By now, any user will have saved the ‘tbody’ by making the use of the find_all() method which is also provided by the beautifulsoup library.
The thing is that as of now the required data is situated in two different tables and therefore, the user will need to get this required data by making the use of the same lines of the code but, the variable to be used this time will be different as shown below :
# getting tables from the content
try:
table = data[0].find_all('tr')
except:
table = None
try:
table_1 = data[1].find_all('tr')
except:
table_1 = None
6. In the next step, the data will be extracted and saved from the tabular data present on the website, and therefore, to serve this purpose, many dictionaries are made.
In our example of the created dictionary, keys will be the name that is provided to the saved values, and also values is the one which contains the actual and true values.
This is how it can be done below with only a simple code that is easy to comprehend :
# declare empty dictionary
final_dict = dict()
for i in range(0,len(table)):
try:
table_name = table[i].find_all('td')
except:
table_name = None
final_dict[table_name[0].text] = table_name[1].text
for i in range(len(table_1)):
try:
table_name = table_1[i].find_all('td')
except:
table_name = None
final_dict[table_name[0].text] = table_name[1].text
7. And also, the result will be something like this :
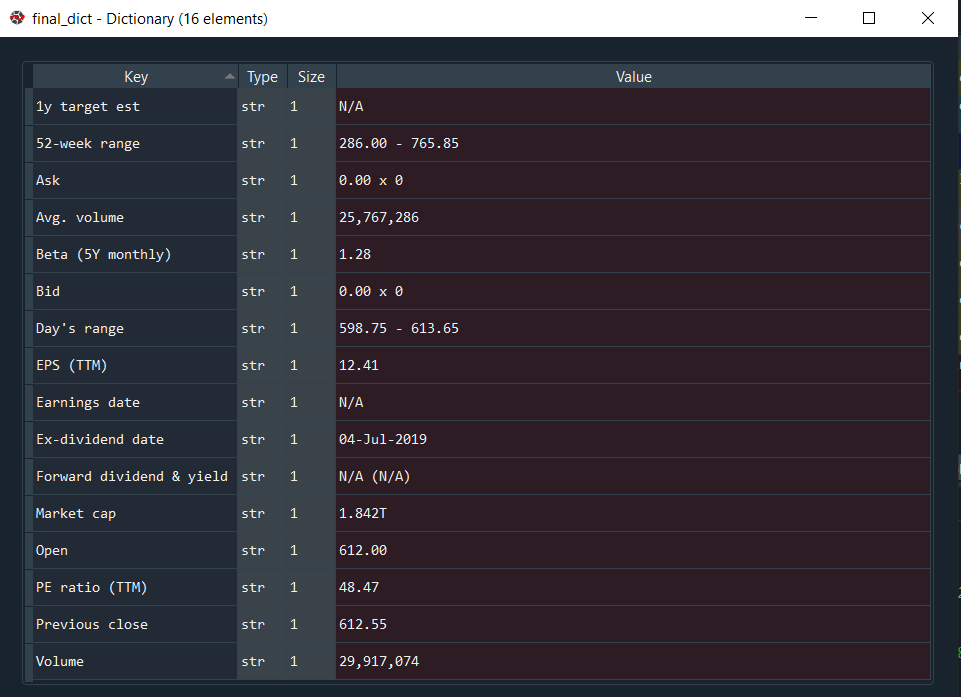
According To Our Understanding :
With this guide, it will be easy for any user to get any process of scraping information from any website including Yahoo Finance, fully automated without much disturbance and hassle and minimum line of codes.
We at Scrapingpass.com have shown you for educational purposes the ways and means of scraping any required information from Yahoo Finance in a simple and easy way that can be understood by anyone. You can check more tools here.
Describing the whole process in an efficient way possible, we have shown you how you can scrape data from Yahoo Finance using our methodology and tools.




Abhishek Kumar
More posts by Abhishek Kumar