

What Is Web Scraping?
The process where a user collects data and other information that is relevant for him from any website can be termed as web scraping.
It is most widely used in cases of LinkedIn and other such websites. While it is illegal to perform scraping with permission from the website owner, this article is mostly for educational purposes and hence, no illegal scraping is being promoted.
There are cases when people don’t want to see all the things that are contained in a website. In such a case, our services can be of great help. This is because we have developed the aptest and efficient way to extract data from various websites without much trouble.
We at Scrapingpass.com have a team of experts that have perfected the way from the extraction of information even from Amazon.com. This isn’t easy to achieve.
The coding behind this methodology of scraping of required data from any website is regressive coding and efficient implementation. It was the consistency to achieve that led us to build a reliable platform.
Therefore, we can say that we provide one of the best web scraping technology and follow a strict algorithm. Our goal is that each user should be able to perform scraping and know the related tech behind it.
In order of this concept, we have certain libraries that can be used efficiently.
Libraries Used Commonly :
1. Requests :
It is one of that library which has the capability to extract the given information from the URL that has been provided to it.
The content along with its HTML tags and all the links that are present in the webpage are extracted with the help of this library with great efficiency.
2. BeautifulSoup :
The raw text which is now extracted with the BeautifulSoup needs to be converted into an HTML tree so that it can be read by the user easily.
This is a very important step. It cannot be missed. This is what makes BeautifulSoup quite efficient and important this step. This is where the first step towards scraping is born. The first command exists here, in BeautifulSoup.
The user must implement the installation of the open-source library called ‘request’. The command to be used is given below:
“pip install requests”
This needs to be entered in BeautifulSoup to further the process of web scraping.
Let’s Consider An Example Of Web Scraping :
This is where we will showing the process of scraping with the help of the libraries mentioned above. The process is for educational purposes again, as mentioned before.
Any illicit use of the technique should not be implemented. This is because it is not legal to scrape any owner’s website without his official statement of approval.
So, for educational purposes, we will be scraping the site with the URL: ‘https://www.python.org/. This is where the information that the user requires is stored.
We will be scraping the site for the number of titles that are present in its structure. This is where we need to make the move for extraction of the content in the webpage.
This is also an essential step and hence, nothing must go wrong in each of the cases. There is a method that needs to be used to extract the raw HTML from the webpage which is given below :
“requests.get()”
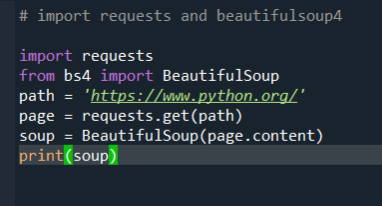
# import requests and beautifulsoup4 import requests from bs4 import BeautifulSoup url = "https://www.python.org/" # using requests to get the content on the webpage page = requests.get(url) # get content of the page into a container named 'soup' soup = BeautifulSoup(page.content,'lxml')
It is clear from the above results that this command that is given as the input will provide the user with a plain text of the entire HTML file. This is what we sought to achieve.
If you use this method to extract any information from ‘https://www.python.org/, you should expect this result. The form could be different depending on different versions.
Now, thereafter, the next step comes in. The text version is to be converted into an HTML tree with the tools with having. This is where another magic happens.
BeautifulSoup4 and parser are used to implement this step and get the appropriate results we need. But, here’s the catch. The output we have received is not ready yet.
We have to first further examine and evaluate the received output. This is a necessary step before the extraction of data can be done from the output. This is because the output we have received for now is not in the format we need it in. The format is of the type String.
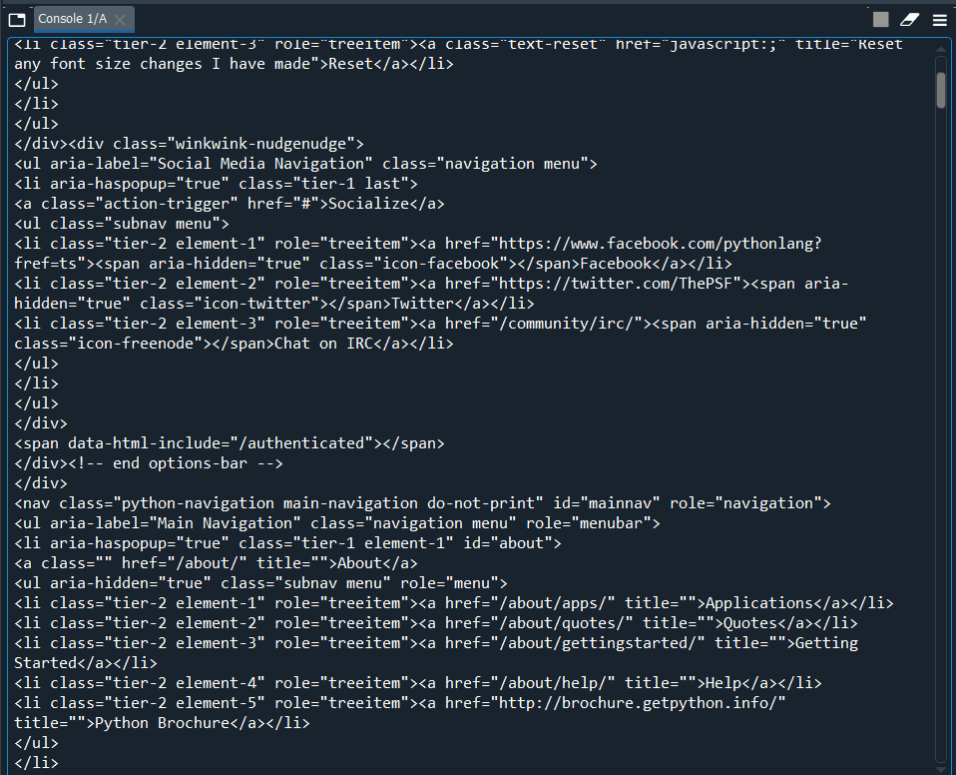
This is the raw textual data using requests.get() that you will receive
Here’s the next step. The plain text is not the output we need and we need to parse it to structure it into an HTML tree. But, if we need to proceed further, we will have to give the necessary response to the parser.
This is how we can see the needed output in the proper indentation structure with the help of a function that is listed below :
“.prettify()“
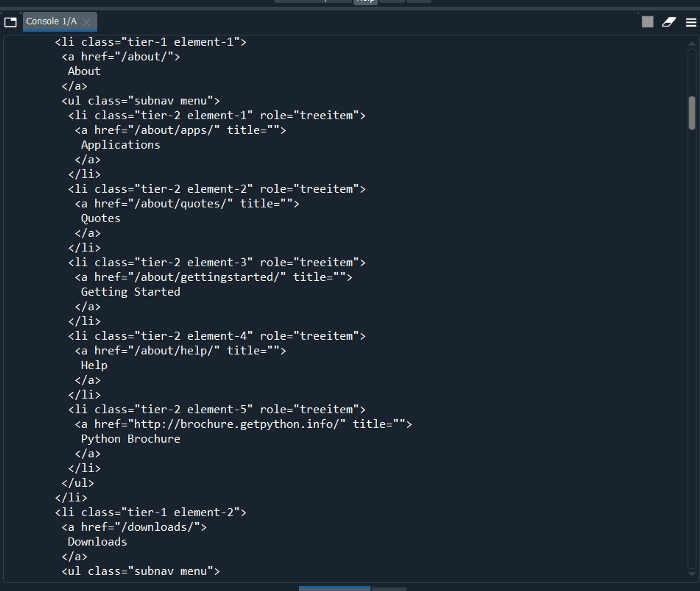
This is the HTML tree-based structure that we wanted for so long
This is where we will now search for the needed information, ie, the required tag.
Now we have the parsed HTML object we can now search for the required element. Like in our case we want to get all the upcoming events on the page.
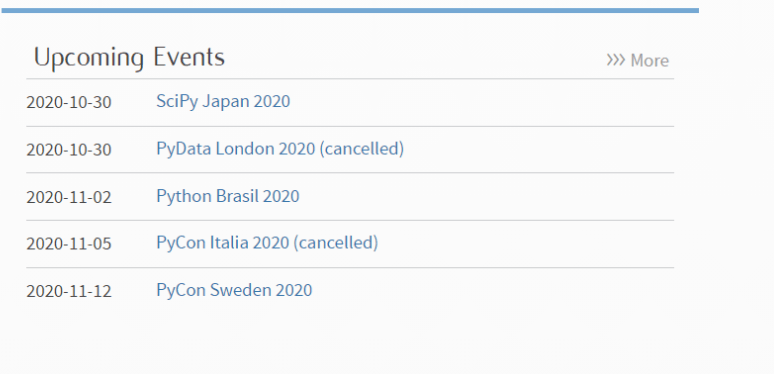
This is the target page from where we wanted to scrape the necessary information
Now by using the developer tools feature and hover over the content to get the class and attributes we wanted to scrape. Then, using the class name and the below command we will be having the elements we want.
container = soup.find("div",{"class":"medium-widget
event-widget last"}).find_all('ul')
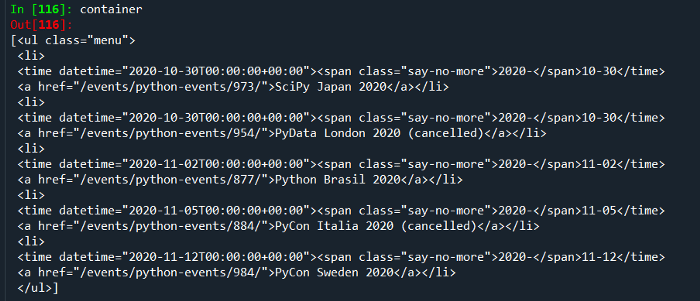
List of all the needed elements
As we have all the list values, we just need to get the context out of it and save it into a list. For this, we will be using list comprehension.
List comprehension is an elegant way to define and create lists based on existing lists. It is generally more compact and faster than normal functions and loops for creating a list.
events = [li.contents[0] for ul in container for li in ul.find_all('a')]
Thereafter, using the above statement we can save all the events into a list named ‘events’. Its output can be seen below.
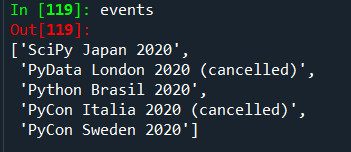
The final list of the elements
And Voila!
We have shown you how to create a web crawler to implement the concept of Web scraping without any effort. This is quite easy and can be done with the help of minimum coding skills.
To Summarize The Above-Mentioned Concept:
We at Scrapingpass.com have successfully implemented the concept of web scraping for education. The experts in our team have designed web crawlers and spider bots that can easily help you out.
The goal of scraping should be to extract reliable information in the form of text or CSV. You can check more here.
While you are implementing the usage of spider bots and crawlers, you should be careful and implement the usage with perfection. Any kind of error could damage the whole operation.
While it is not quite easy to implement this, it would be surely easy to operate with the help of our web crawlers and bots. With the help of our services, it will surely be easy for you to scrape any website you want.




Abhishek Kumar
More posts by Abhishek Kumar